Abstract
Weakly supervised object localization (WSOL) is a task of localizing an object in an image only using image-level labels. To tackle the WSOL problem, most previous studies have followed the conventional class activation mapping (CAM) pipeline: (i) training CNNs for a classification objective, (ii) generating a class activation map via global average pooling (GAP) on feature maps, and (iii) extracting bounding boxes by thresholding based on the maximum value of the class activation map. In this work, we reveal the current CAM approach suffers from three fundamental issues: (i) the bias of GAP that assigns a higher weight to a channel with a small activation area, (ii) negatively weighted activations inside the object regions and (iii) instability from the use of the maximum value of a class activation map as a thresholding reference. They collectively cause the problem that the localization to be highly limited to small regions of an object. We propose three simple but robust techniques that alleviate the problems, including thresholded average pooling, negative weight clamping, and percentile as a standard for thresholding. Our solutions are universally applicable to any WSOL methods using CAM and improve their performance drastically. As a result, we achieve the new state-of-the-art performance on three benchmark datasets of CUB-200-2011, ImageNet-1K, and OpenImages30K.
Weakly Supervised Object Localization
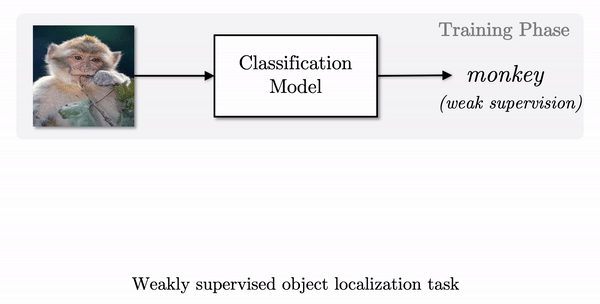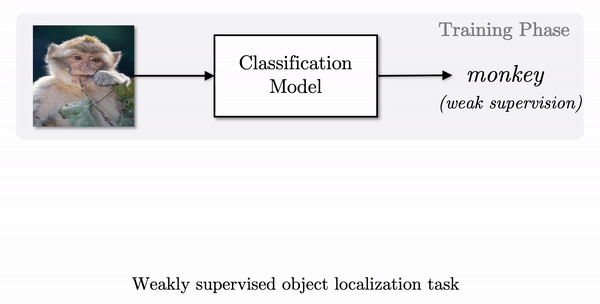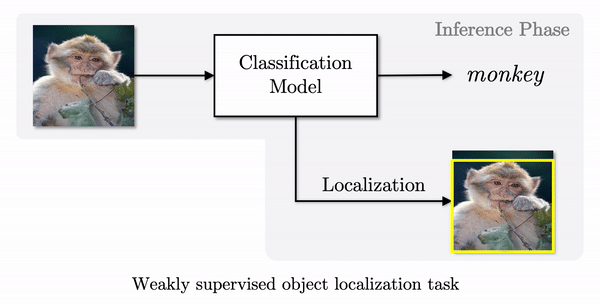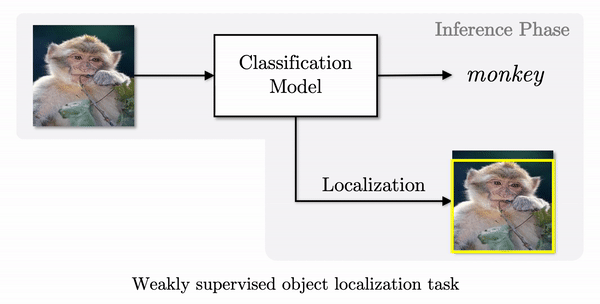
Weakly Supervised Object Localization (WSOL) is a task to localize an object only using image-level class labels. Therefore, our goal is to precisely locate an object in an image using a classification model trained on image-level class labels without having annotations for object location.
Class Activation Mapping
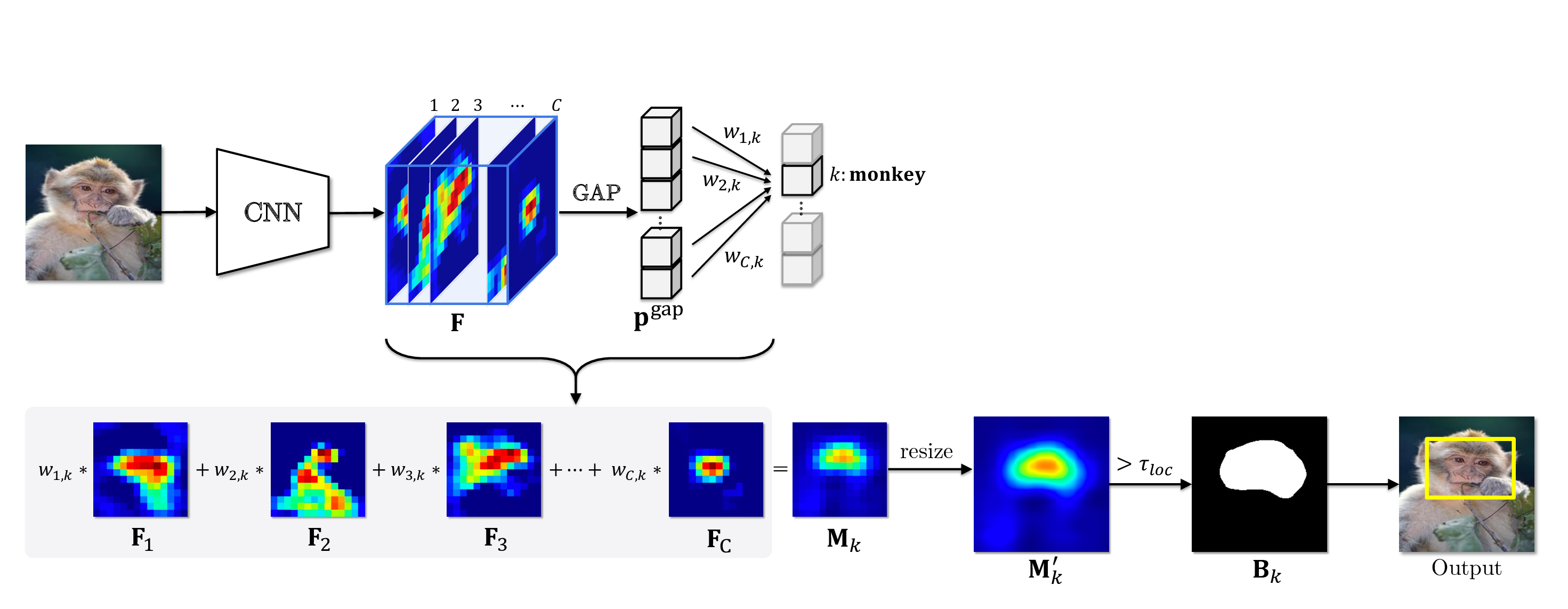
To solve WSOL problems, class activation mapping (CAM) has been widely employed in most of WSOL algorithms. It works in the following ways.
- In training time, a classifier is trained only using image-level class labels.
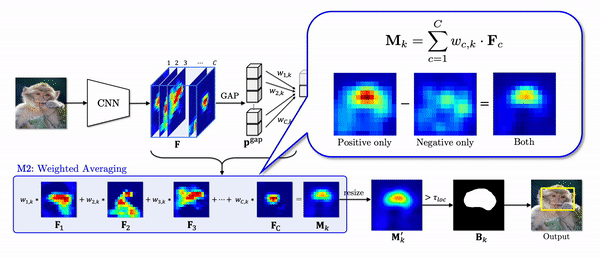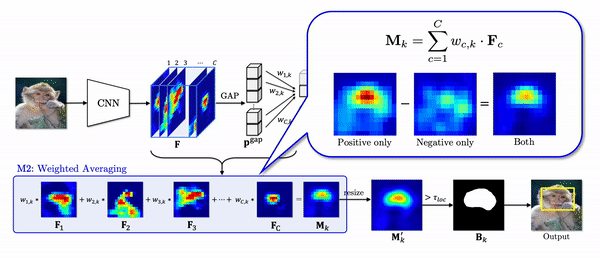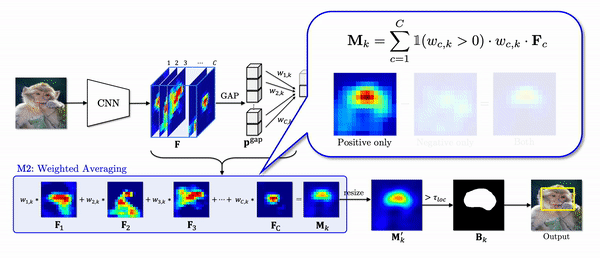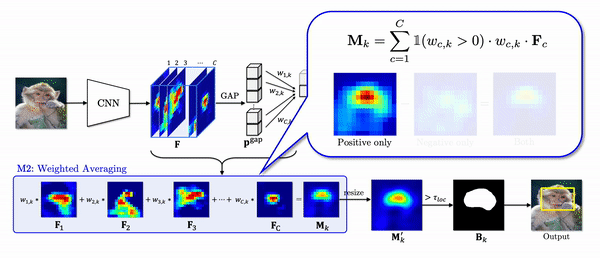
- In inference time, a class activation map is generated by weighted-averaging a feature map F, and the corresponding weight W in channel-wise.
- Then a binary mask B is produced through thresholding from which an object location is estimated in the format of a bounding box.
Problems
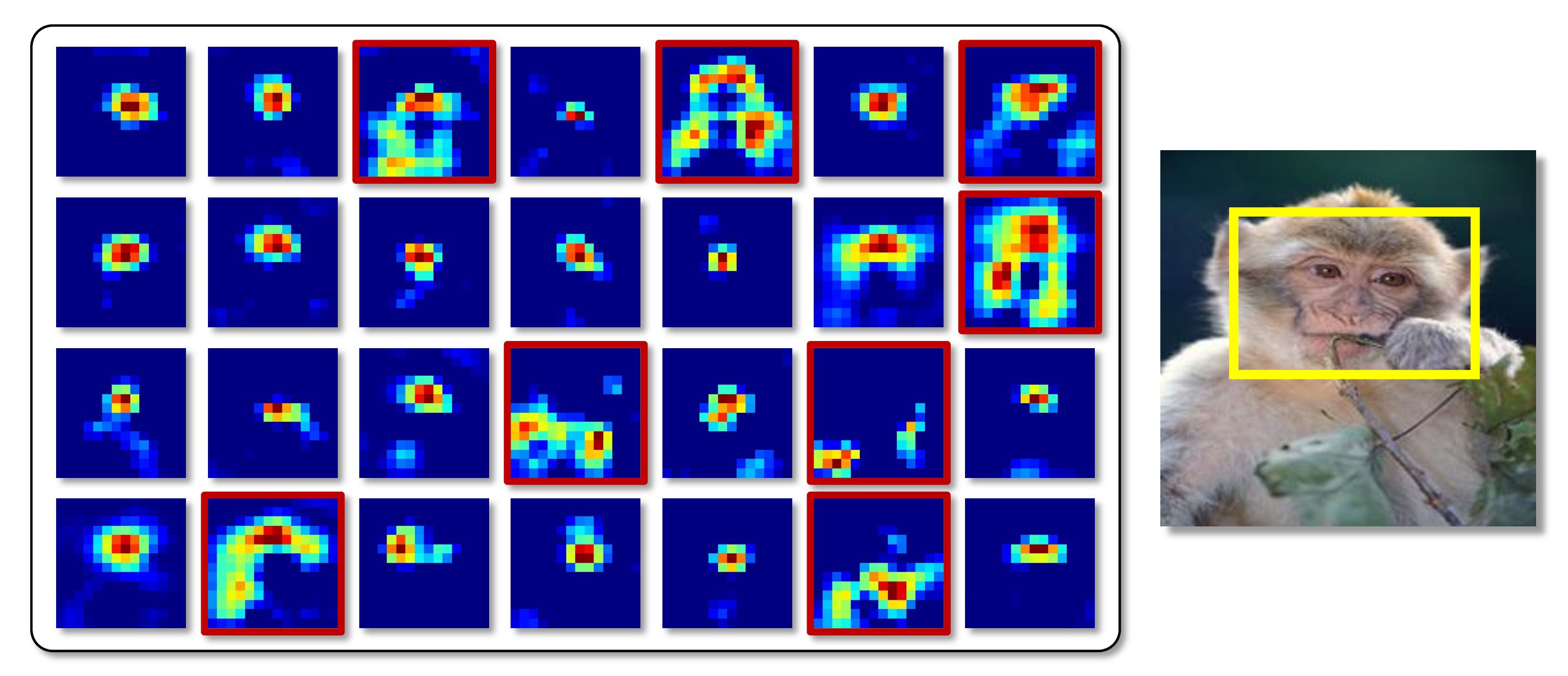
Despite the universal use of CAM, the localization results from CAM tend to be limited to a small discriminative region as shown in the example of the monkey. To figure out the cause of this phenomenon, let’s closely look at the features which are the core ingredients of the localization. The below figure shows 28 features of a feature map F. We can see that a large number of them are highly activated in the small discriminative region. The problem of limited localization originates from the characteristics of a classification model. To classify a monkey, the classifier only needs to look at a small discriminative region such as the head of the monkey.
Previous Works
To resolve this issue, most previous methods of WSOL have attempted to expand the activations of the features towards non-discriminative object regions.
For example, ADL masks out highly activated regions of a feature map in training time expecting the activations to spread out to the whole object region.
However, if we closely look at the features in the red boxes above, the information that captures the whole object region already exists in a feature map.
Hence, instead of endeavoring to expand the activations by devising a new architecture as done in the previous works, in this paper, we propose a solution to properly utilize this information to capture the whole object region.
Our Approach
To this end, we first demonstrate that the CAM pipeline improperly processes the features in three different modules. Then we introduce methods to replace each of the corresponding modules in the CAM pipeline.
1. Thresholded Average Pooling (TAP)
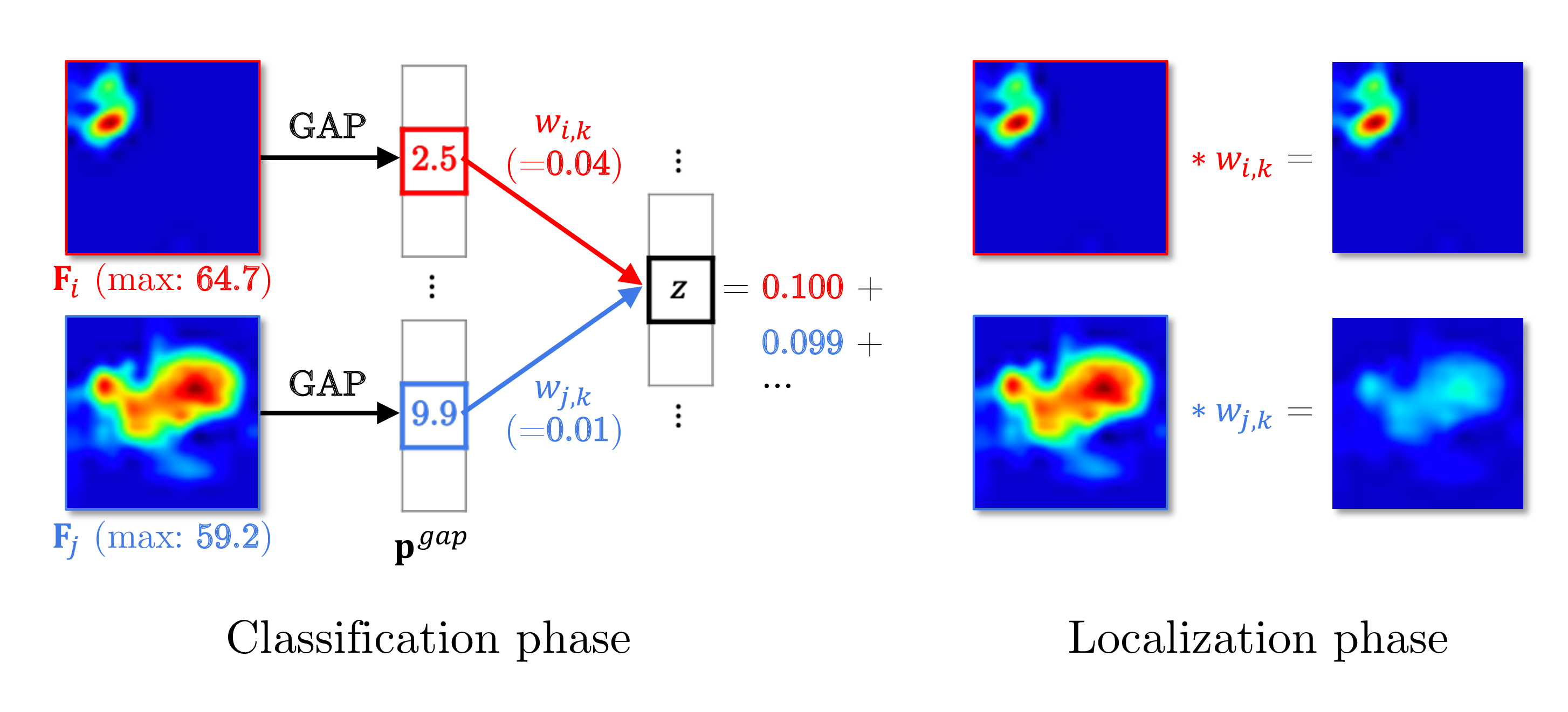
Global average pooling (GAP) in the CAM pipeline does not take into account the different activated area of each feature as shown in the equation of pgapc which denotes a pooled feature through GAP.
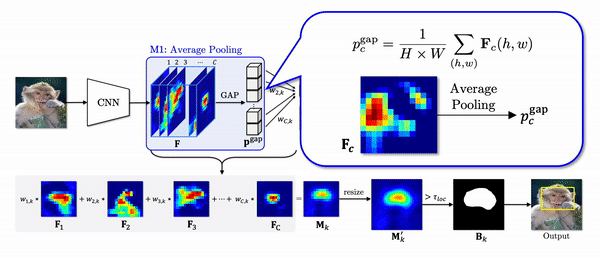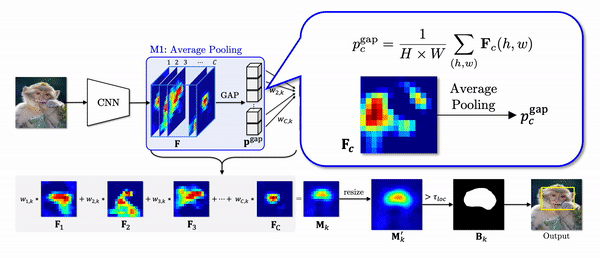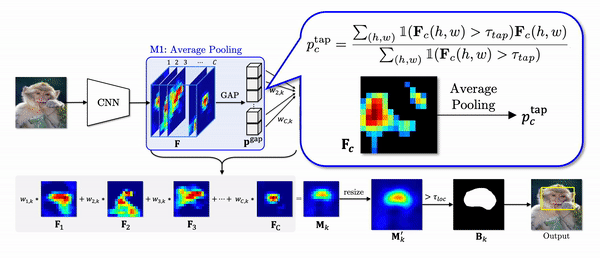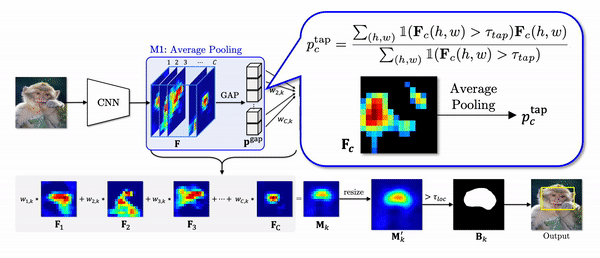
To elaborate this statement, let’s look at the example below. Due to small activated area of Fi, after GAP, the value corresponding to Fi is largely underestimated compared to that of Fj although the maximum values are similar. Despite almost equal contributions of two features to logit z as 0.1 and 0.099, the weights are trained to be highly different to compensate for the difference introduced by the GAP. In localization phase, we can verify the weighted feature with a small activated region is highly overstated.
Instead of using GAP, we propose thresholded average pooling (TAP) which average-pools only the activations greater than a threshold proportional to the maximum value of each channel. In the gif above, the region in black is not considered for pooling. Thus, TAP average-pools each channel without over or underestimating it.
2. Negative Weight Clamping (NWC)
As shown in the second module (M2) in the figure, the CAM naively weighted sum all the features although the features corresponding to the negative weights are mostly activated in the object region, especially less discriminative region.
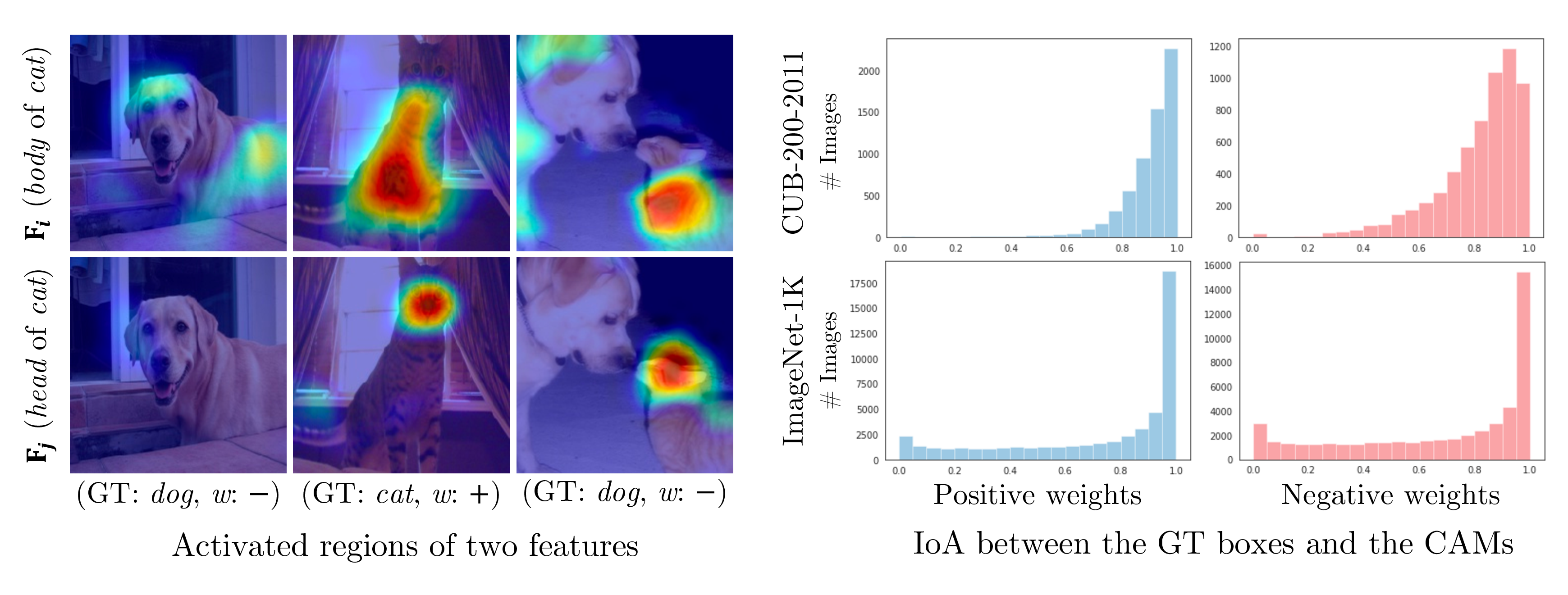
To understand this phenomenon, let’s look at an example below (left). Fi and Fj capture the body and head of the cat, respectively. Although the corresponding weight of Fi is negative in the image of a dog, it is activated in the body of the dog. On the other hand, Fj is not activated in the region of the dog. It is because the less discriminative feature such as Fi is shared between different classes. Therefore, a class activation map of a dog including Fi loses activations in the body part.
The histograms below (right) show the intersection over area between the ground truth boxes and class activation maps generated from positive and negative weights. Surprisingly, a majority of the features with the negative weights are activated inside the object region as similar to the positive weights.
Instead of naively weighted averaging all the features, we propose negative weight clamping (NWC) which simply clamps all the negative weights to zero. As a result, NWC produces a class activation map only using the features corresponding to the positive weights as shown the gif above. In this way, we can prevent the features with negative weights from depreciating the activations in the object region.
3. Percentile as a Standard (PaS)
The last problem of CAM we have addressed is a thresholding module (M3). In the CAM pipeline, a binary mask is generated to make a prediction on the location of an object. To this end, it uses the threshold which is proportional to the maximum value of a class activation map. However, the maximum as a standard often makes the threshold to be too high.
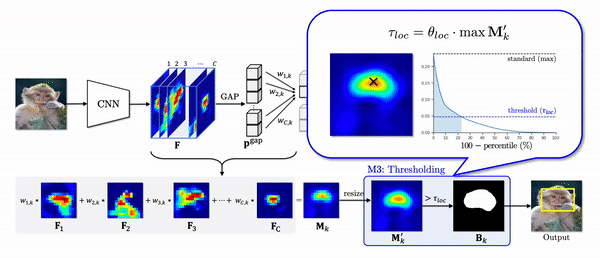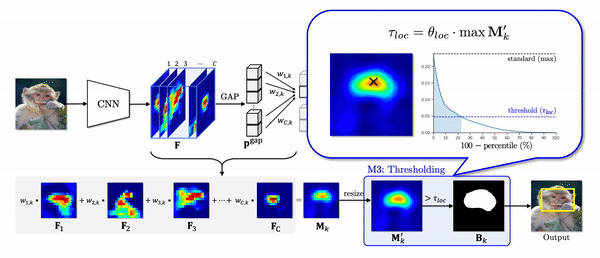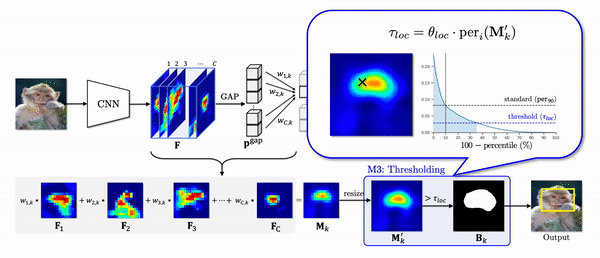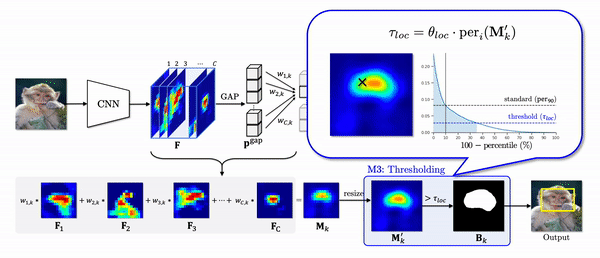
In the figure below, for an image, 2nd column shows the number of features of which activations are greater than a threshold. If we see the values of a class activation map in descending order (3rd column), when the high activations are highly overlapped in a small region as in the first row, they exponentially decrease. In this case, since the maximum value is too high, the threshold is also high so that only 23% of activations are included in a localization prediction. As a result, it only captures the head of the dog as shown in the green box.
On the other hand, when the high activations widely spread out throughout the whole object region, the values linearly decrease so that about 40% of activations are included in a localization prediction. Instead of using the maximum value as a standard, If we use 90-th percentile as a standard, the pattern of the class activation map values become very similar, and about the same number of activations are included in a localization prediction. As a result, the final predictions capture the object region more accurately as shown in the yellow box.
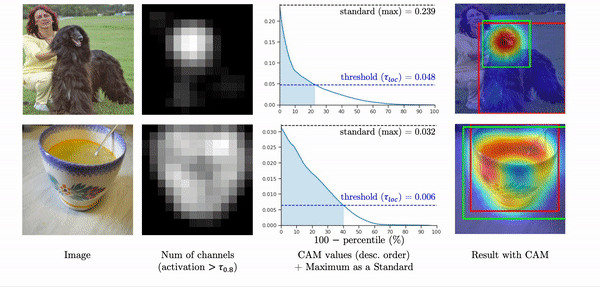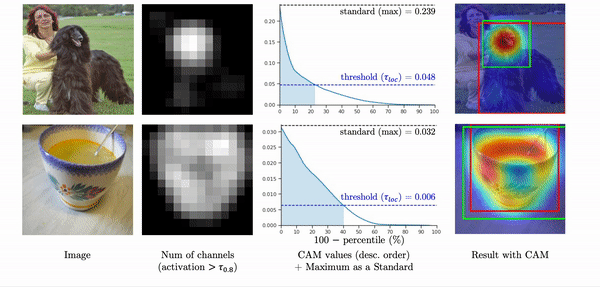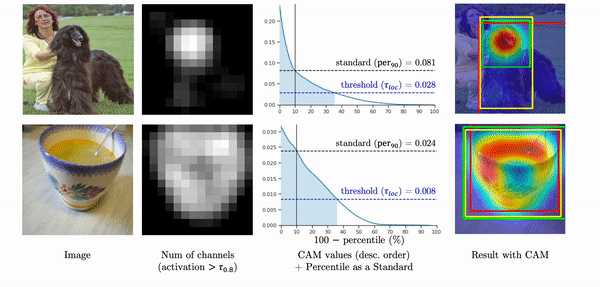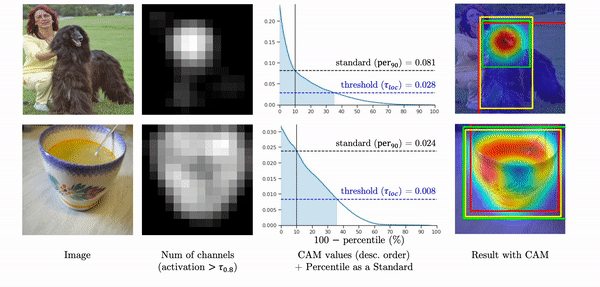
Thus, instead of using the maximum as a standard,
we propose the percentile as a standard (PaS) since it determines the threshold much more robustly regardless of the overlap of high activations.
Experiment Results
To verify the effectiveness of the proposed methods, we did some experiments on two conventional benchmark datasets, CUB-200-2011 and ImageNet-1K, and one recently proposed one called Openimages30K.
Quantitative Results
To validate the robustness of the proposed method, we provide some quantiative results on (a) different combinations of the proposed components - TAP, NWC and PaS, (b) different backbone structures - V: VGG16, R: ResNet50, M: MobileNet, G: GoogleNet, and (c) other SOTA algorithms - HaS and ADL, as shown below.
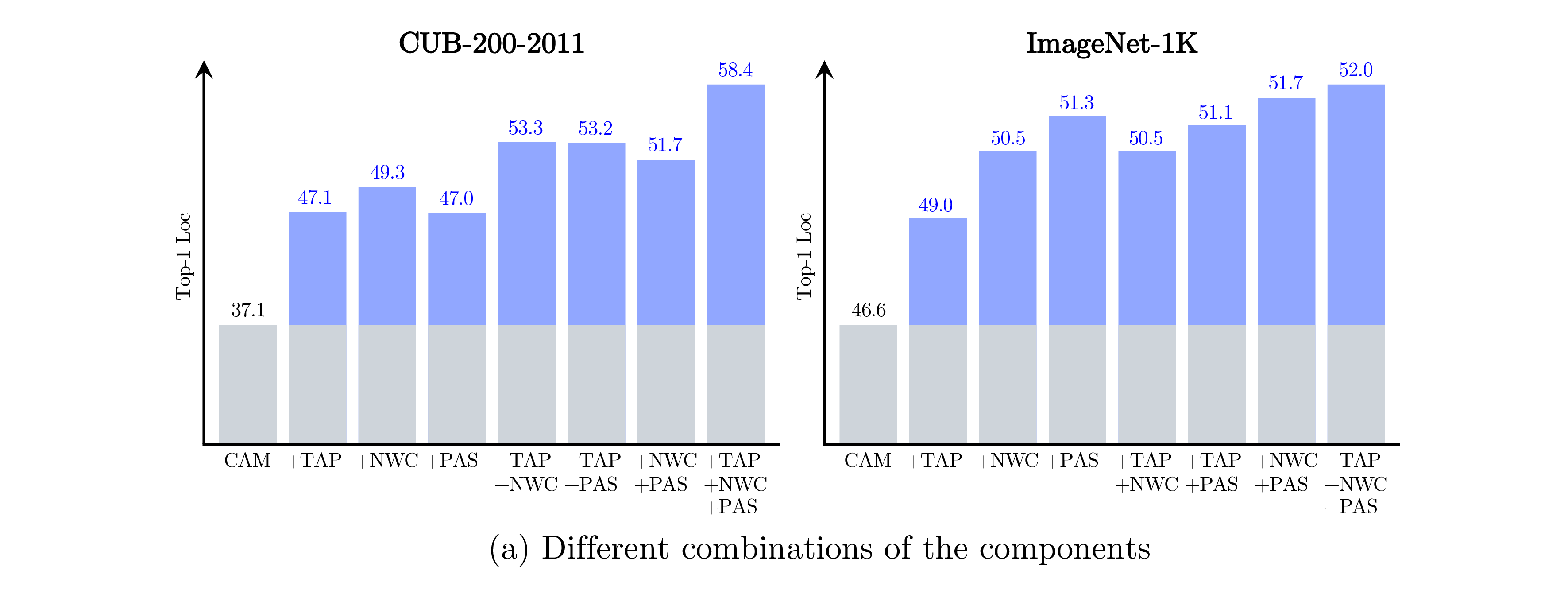
From (a), we see that TAP, NWC and PaS consistently improved the localization performance, and with all the components applied, the localization performance further improved.
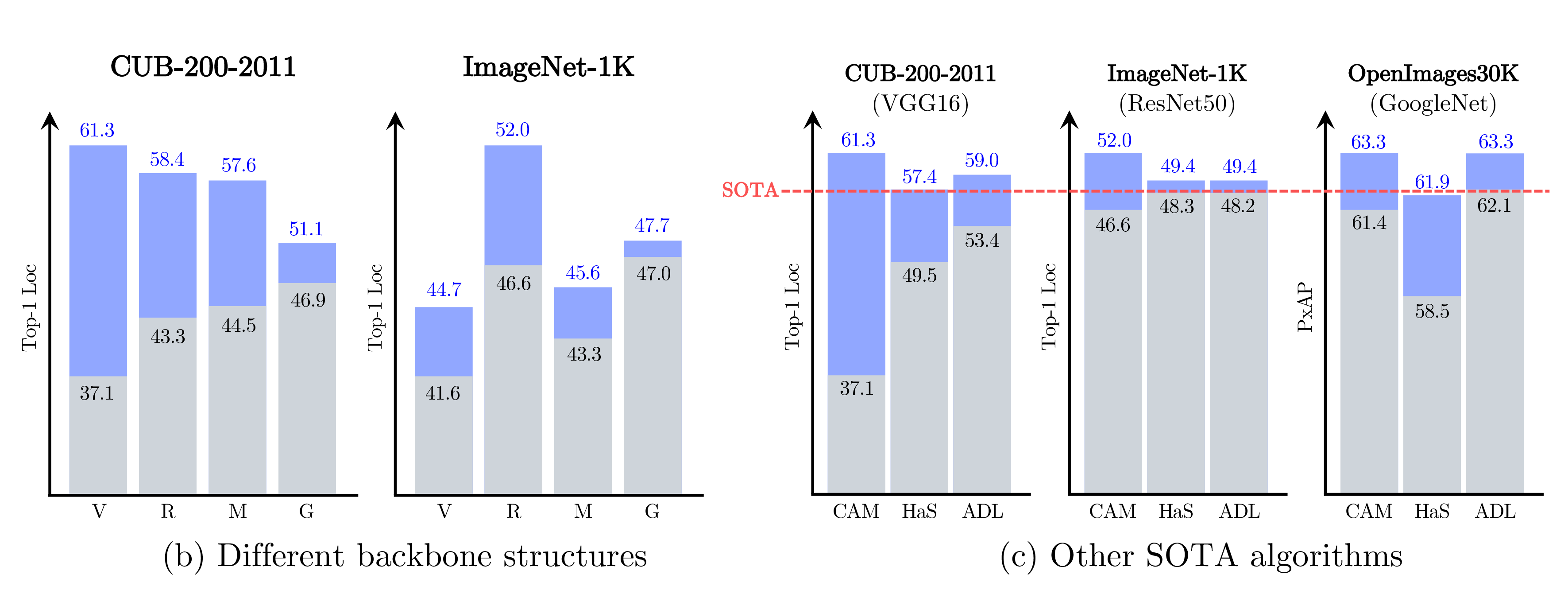
We also applied the proposed method to VGG16, ResNet50, MobileNet and GoogleNet as shown in (b). From this, We verified that the proposed method consistently improved the localization performance regardless of the backbones.
Since the proposed method is applicable to any CAM-based WSOL algorithms, we applied it to other state-of-the-art CAM-based methods. On the various combinations of datasets, backbones and SOTA methods, our proposed method significantly improved the localization performance, and we also achieved the new state-of-the-art performance as illustrated in (c).
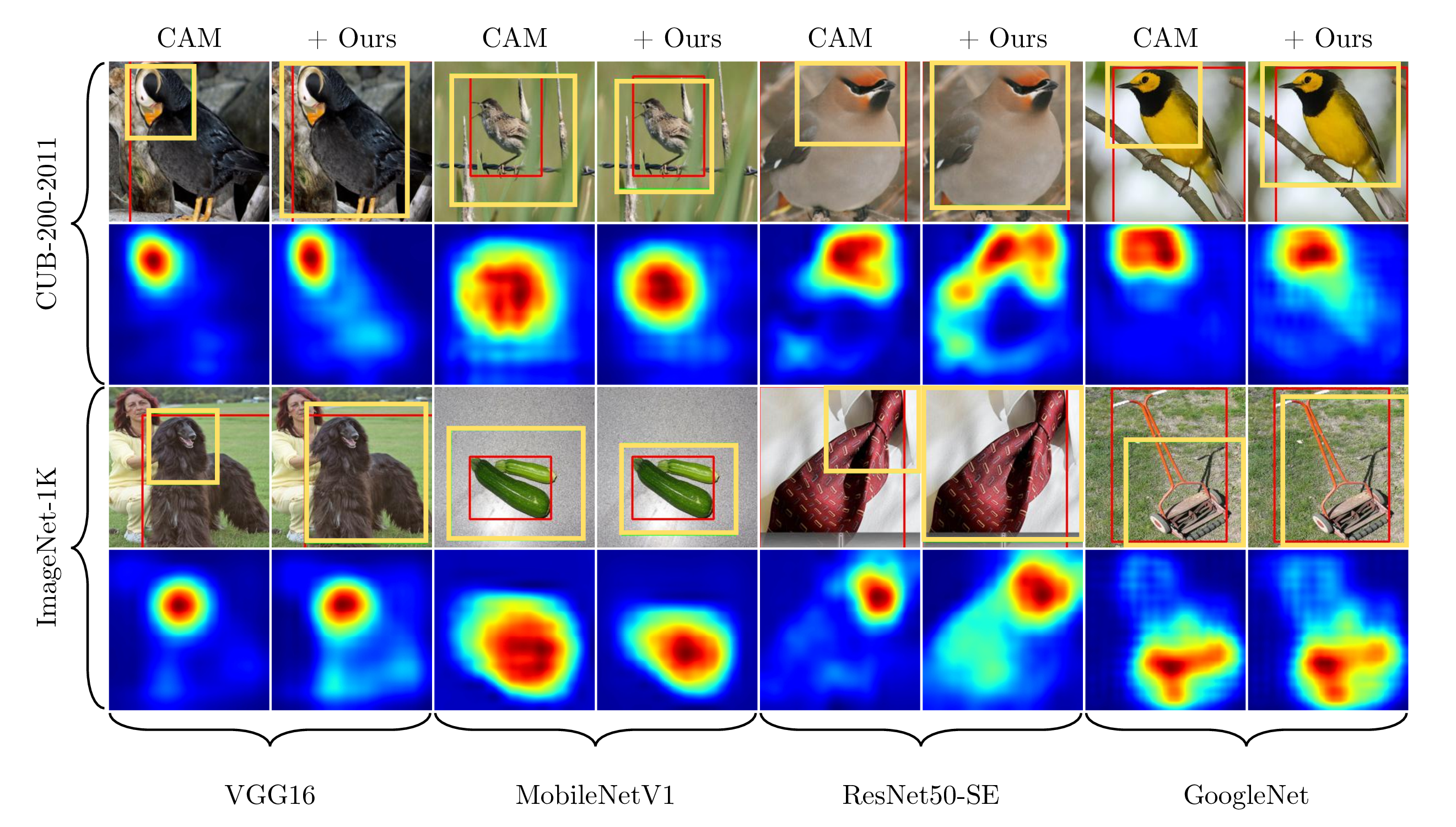
Qualitative Results
Finally, here are some qualitative results. We can see that the prediction results of CAM are limited to a small discriminative region as shown in the yellow box. Also, its class activation maps are mostly activated in the small region. On the other hand, the proposed method generates class activation maps that are activated throughout the whole object region, and as a result, it gives much better predictions.
Challenge Results
We participated in weakly supervised object localization (WSOL) and semantic segmentation (WSSS) challeges hosted by the 2nd Learning from Imperfect Data (LID) workshop in CVPR 2020.
Using the proposed method, we achieved the 1st and 2nd places in WSOL and WSSS tasks, respectively.
Conclusion
In summary,
- we demonstrated the underlying issues of CAM and the mechanism of them making the localization to be limited to a small discriminative region.
- From this analysis, we proposed three solutions that alleviate the issues in each of the corresponding modules of CAM.
- Lastly, we verified our proposed method consistently improved the localization performance regardless of datasets, backbones and CAM-based methods, and achieved the new state-of-the-art performance on all three benchmark datasets.
Acknowledgements
We appreciate Hyunwoo Kim and Jinhwan Seo for their valuable comments.
This work was supported by AIR Lab (AI Research Lab) in Hyundai Motor Company through HMC-SNU AI Consortium Fund,
and the ICT R&D program of MSIT/IITP (No. 2019-0-01309, Development of AI technology for guidance of a mobile robot to its goal with uncertain maps in indoor/outdoor environments and No.2019-0-01082, SW StarLab).
Citation
@InProceedings{Bae:2020:RethinkingCAM,
author = {Bae, Wonho and Noh, Junhyug and Kim, Gunhee},
title = {Rethinking Class Activation Mapping for Weakly Supervised Object Localization},
booktitle = {European Conference on Computer Vision (ECCV)},
month = {August},
year = {2020}
}
@InProceedings{Bae:2020:RevisitingCAM,
title = {Revisiting Class Activation Mapping for Learning from Imperfect Data},
author = {Bae, Wonho and Noh, Junhyug and Seo, Jinhwan and Kim, Gunhee},
booktitle = {2nd LID workshop at Conference on Computer Vision and Patter Recognition (CVPR)},
month = {June},
year = {2020}
}